Tidytuesday 2020-04-21: agregaciones a varios niveles
Introducción
En este post vamos a ver cómo trabajar con distintos niveles de agregación de los datos con las distintas funciones de dplyr. Para ello, usaremos los datos propuestos para el #TidyTuesday (2020-04-21) sobre multas establecidas en torno a la GDPR tal y como aparecen en la web Privacy Affairs (para más información sobre los tipos de multa que recoge la GDPR: What are the GDPR Fines?).
El dataset original recoge en cada fila información sobre casos sancionados por incumplimiento de la GDPR; en cada caso se ha infringido un mínimo de un artículo, pero pueden ser más (aparecen recogidos en la columna articles).
Además de los datos del #TidyTuesday, hemos recopilado otro pequeño conjunto de datos (niveles_multas.csv), que se han obtenido manualmente en la web General Data Protection Regulation y que tiene las siguientes variables:
- Número del articulo
- Nivel de multa (1 hasta 10.000.000€, 2 hasta 20.000.000€)
- Capítulo en el que aparece el artículo
- Título del artículo
El objetivo es crear varios gráficos que muestren qué articulos han sido los más infringidos, cuáles no se han infringido, cuantías, etc. Para eso, antes de poder crear los gráficos tendremos que transformar la estructura de los datos.

Resultado final (con mínima edición en gimp)
Librerías
En primer lugar, cargamos las librerías que vamos a utilizar.
- Cargamos el paquete
tidyverseya que vamos a usar varios de sus componentes: ggplot, dplyr… - Treemapify: extensión de ggplot para crear treempaps
- ggtext: paquete para poder formatear con Markdown y HTML los diversos textos de un gráfico.
- Patchwork: extensión para maquetar varios gráficos.
library(tidyverse)
library(treemapify)
library(ggtext)
library(patchwork)
library(here)Cargar los datos
gdpr_raw <- readr::read_tsv("https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2020/2020-04-21/gdpr_violations.tsv")
head(gdpr_raw)## # A tibble: 6 x 11
## id picture name price authority date controller article_violated type
## <dbl> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr>
## 1 1 https:~ Pola~ 9380 Polish N~ 10/1~ Polish Ma~ Art. 28 GDPR Non-~
## 2 2 https:~ Roma~ 2500 Romanian~ 10/1~ UTTIS IND~ Art. 12 GDPR|Ar~ Info~
## 3 3 https:~ Spain 60000 Spanish ~ 10/1~ Xfera Mov~ Art. 5 GDPR|Art~ Non-~
## 4 4 https:~ Spain 8000 Spanish ~ 10/1~ Iberdrola~ Art. 31 GDPR Fail~
## 5 5 https:~ Roma~ 150000 Romanian~ 10/0~ Raiffeise~ Art. 32 GDPR Fail~
## 6 6 https:~ Roma~ 20000 Romanian~ 10/0~ Vreau Cre~ Art. 32 GDPR|Ar~ Fail~
## # ... with 2 more variables: source <chr>, summary <chr>Como ya se ha indicado, el archivo niveles_multas.csv recoge información complementaria sobre los artículos de la GDPR.
niveles <- read_csv(here("static","data","niveles_multas.csv"))
head(niveles)## # A tibble: 6 x 4
## articles level chapter title
## <dbl> <dbl> <chr> <chr>
## 1 4 0 General provi~ Definitions
## 2 5 2 Principles Principles relating to processing of personal d~
## 3 6 2 Principles Lawfulness of processing
## 4 7 2 Principles Conditions for consent
## 5 8 1 Principles Conditions applicable to child's consent in rel~
## 6 9 2 Principles Processing of special categories of personal da~Preparar los datos
Para poder crear los gráficos, vamos a tener que modificar la estructura de los datos de tal forma que cada fila recoja información de un artículo de la GDPR, y no de un caso sancionado.
Una vez hayamos cambiado la estructura, podremos realizar cálculos a distintos niveles de agregación de los datos; por ejemplo, porcentaje de las cuantias de cada artículo con respecto al total, con respecto al tipo de multa…
Cambiar la estructura
Para cambiar la estructura de los datos vamos a partir del post de Julia Silge Modeling #TidyTuesday GDPR violations with tidymodels. Para cambiar la estructura, primero extrae los artículos de la variable articles_violated con str_extract_all() (se crea un vector de tipo cadena con los resultados obtenidos) y posteriormente usa la función unnest() sobre esa nueva variable (asigna una fila a cada valor del vector; el resto de datos se copian de la fila original).
Como más adelante vamos a querer calcular las cuantías de las multas agrupadas por distintas variables, tenemos que corregir la variable price, ya que de otra forma puede en algunos casos el valor original se duplicará, triplicará… dependiendo del número de artículos que hubiera infringido originalmente. A falta de un dato desagregado por artículos, lo que hacemos es dividir la cuantía total de cada caso entre el número de artículos infringidos en cada caso.
gdpr_tidy <- gdpr_raw %>%
transmute(
id,
price,
article_violated,
articles = str_extract_all(
article_violated,
"Art. ?[:digit:]+"
)
) %>%
mutate(total_articles = map_int(articles, length)) %>%
unnest(articles) %>%
mutate(articles = as.numeric(str_extract(articles, "\\d+")),
price = price / total_articles)
head(gdpr_tidy)## # A tibble: 6 x 5
## id price article_violated articles total_articles
## <dbl> <dbl> <chr> <dbl> <int>
## 1 1 9380 Art. 28 GDPR 28 1
## 2 2 625 Art. 12 GDPR|Art. 13 GDPR|Art. 5 (1) c) G~ 12 4
## 3 2 625 Art. 12 GDPR|Art. 13 GDPR|Art. 5 (1) c) G~ 13 4
## 4 2 625 Art. 12 GDPR|Art. 13 GDPR|Art. 5 (1) c) G~ 5 4
## 5 2 625 Art. 12 GDPR|Art. 13 GDPR|Art. 5 (1) c) G~ 6 4
## 6 3 30000 Art. 5 GDPR|Art. 6 GDPR 5 2Antes de seguir transformando los datos, vamos a crear otro objeto para obtener la lista de artículos que NO han sido multados. Para ello partimos del conjunto de datos niveles, que contiene la lista con todos los artículos, y usamos anti_join() para quedarnos únicamente con los artículos que no han sido infringidos.
Además, añadimos una nueva variable ranking que más adelante nos permitirá ordenar los elementos en el gráfico correspondiente.
nulos <- niveles %>%
anti_join(gdpr_tidy) %>%
group_by(level) %>%
mutate(ranking = row_number(articles))Las variables y cálculos con los que vamos a trabajar serán:
- Recuento de elementos en los diversos niveles de agregación, y proporciones correspondientes.
- Suma acumulada de las multas por diversos niveles de agregación, y proporciones correspondientes.
Asimismo, vamos a trabajar con tres niveles de detalle:
- A nivel de artículo: nivel más desagregado con el que vamos a crear nuestros gráficos, aunque primero vamos a tener que agregar los datos originales (que realmente están más deagregados, por caso y artículo).
- A nivel de tipo de multa: con tres posibles niveles, los dos marcados por la ley y uno tercero porque tal y como veremos aparecen algunos artículos que no conllevan pena económica.
- A nivel de todo el conjunto de datos (nivel de agregación superior).
Para mantener una lógica a la hora de nombrar las nuevas variables que vamos a generar usaremos el siguiente patrón:
(Variable)_(variables de agrupación (nivel de agregación de los datos))_(cálculo)
En el primer paso usaremos la función summarise() para reestructurar el conjunto de datos original y agregar los datos a nivel de artículo.
datos <- gdpr_tidy %>%
# nivel más granular (23 niveles, uno por cada artículo infringido)
group_by(articles) %>%
summarise(art_n = n(),
price_art_sum = sum(price)) %>%
ungroup()Calcular las nuevas variables
Una vez que ya tenemos nuestra estructura básica, procedemos a realizar los cálculos a distintos niveles de agregación.
datos <- datos %>%
# completamos los datos para poder usar el tipo de multa como agrupación
left_join(niveles) %>%
# nivel intermedio de agregación (3 niveles)
arrange(level, articles) %>% # solo para escanear más fácil la tabla
group_by(level) %>%
mutate(
lev_n = sum(art_n),
lev_n_prop = art_n / lev_n,
price_lev_sum = sum(price_art_sum),
price_lev_n_prop = price_art_sum / price_lev_sum,
lev_n_rank = dense_rank(desc(art_n)),
price_lev_rank = dense_rank(desc(price_art_sum))
) %>%
ungroup()Después de realizar los cálculos en el nivel de agrupación/agregación de interés volvemos a desagrupar los datos, y podemos pasar a otro nivel de agregación.
datos <- datos %>%
# nivel más agregado (1 nivel)
mutate(
tot_n_prop = art_n / sum(art_n),
tot_n_rank = dense_rank(desc(art_n)),
price_tot_sum = sum(price_art_sum),
price_tot_prop = price_art_sum / sum(price_art_sum),
price_tot_rank = dense_rank(desc(price_art_sum))
) Para uno de los gráficos que vamos a crear es necesario realizar una última transformación a la estructura de los datos, ya que para poder crear las líneas correctamente tenemos que pivotar los datos a partir de dos nuevas variables.
Hasta ahora hemos usado la función dense_rank() para conocer el puesto que ocupa cada artículo con respecto a otra variable y en determinado nivel de agregación. Estos datos, sin embargo, no son adecuados para crear un gráfico en el que cada artículo aparezca en una “fila”, que además tiene que estar alineada con otros dos gráficos (los gráficos de barras). En el caso de que haya “empate” entre varios artículos, dense_rank() asigna el mismo ranking, por lo que si usamos dichos valores para posicionar las marcas gráficas, estarán solapadas.
Para que cada marca gráfica tenga su propio espacio y no se solape con el resto, usaremos la función row_number(). Tenemos que crear dos rankings con esta fórmula, uno para el número de apariciones y otro para la cuantía acumulada. Una vez que tengamos esas dos variables, podemos pivotar los datos.
datos_pivot <- datos %>%
select(articles, art_n, price_art_sum, level, tot_n_prop, price_tot_prop, title) %>%
arrange(desc(art_n)) %>%
mutate(puesto_n = row_number()) %>%
arrange(desc(price_art_sum)) %>%
mutate(puesto_price = row_number()) %>%
pivot_longer(starts_with("puesto"), names_to ="pos_X", values_to = "ranking")Crear los gráficos
Gráficos de barras
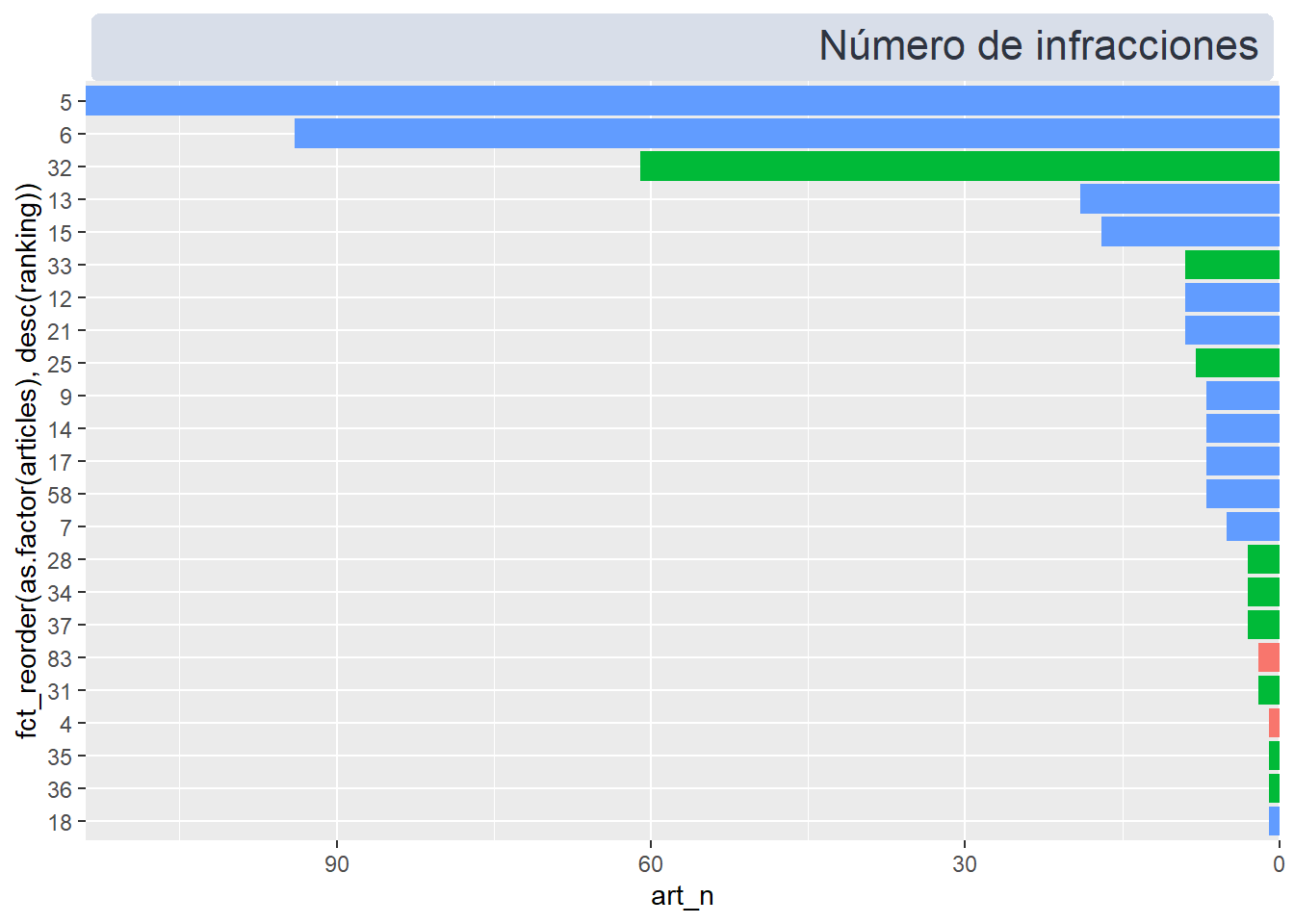
Los dos gráficos de barras son prácticamente, simplemente varía la variable que mapearemos a X: el número de apariciones en el gráfico de la izquierda, y el de la cuantía acumulada en el de la derecha.
Vamos a usar la versión pivotada de los datos, por lo que tenemos que filtrar una de cada dos filas.
IMPORTANTE: para poder usar el operador %>% a la hora de filtrar los datos dentro de ggplot, es necesario que identifiquemos el parámetro data =, ya que de otra forma dará error.
Además, invertimos el eje X del gráfico de la izquierda, y cambiamos los atributos gráficos del título para que aparezca alineado a la derecha (más adelante cambiaremos la alineación de todos los títulos con patchwork)
(
items <-
ggplot(
data = datos_pivot %>% filter(pos_X == "puesto_n"),
aes(art_n, fct_reorder(as.factor(articles), desc(ranking)), fill = as.factor(level))
) +
geom_col() +
scale_x_continuous(trans = "reverse", expand = c(0, 0)) +
guides(fill = FALSE) +
labs(title = "Número de infracciones") +
theme(
plot.title = element_textbox_simple(
color = "#2e3440",
fill = "#d8dee9",
size = 16,
padding = margin(5.5, 5.5, 5.5, 5.5),
width = unit(0.99, "npc"),
halign = 1
)
)
)
(
cuantia <-
ggplot(
data = datos_pivot %>% filter(pos_X == "puesto_price"),
aes(price_art_sum, fct_reorder(as.factor(articles), desc(ranking)), fill = as.factor(level))
) +
geom_col() +
scale_x_continuous(expand = c(0, 0), limits = c(0, max(
datos$price_art_sum
) * 1.025)) +
guides(fill = FALSE) +
labs(title = "Cuantía acumulada")
)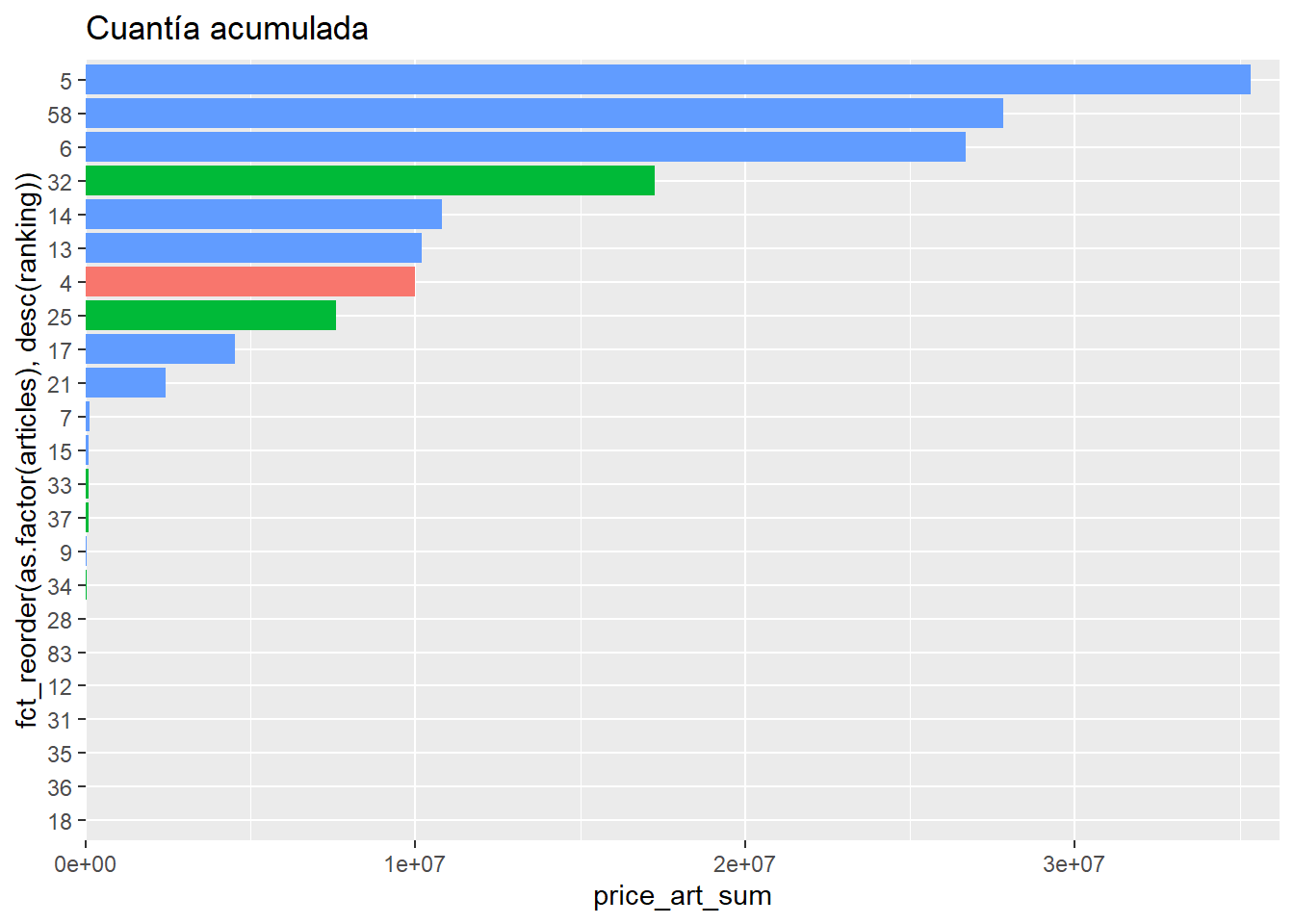
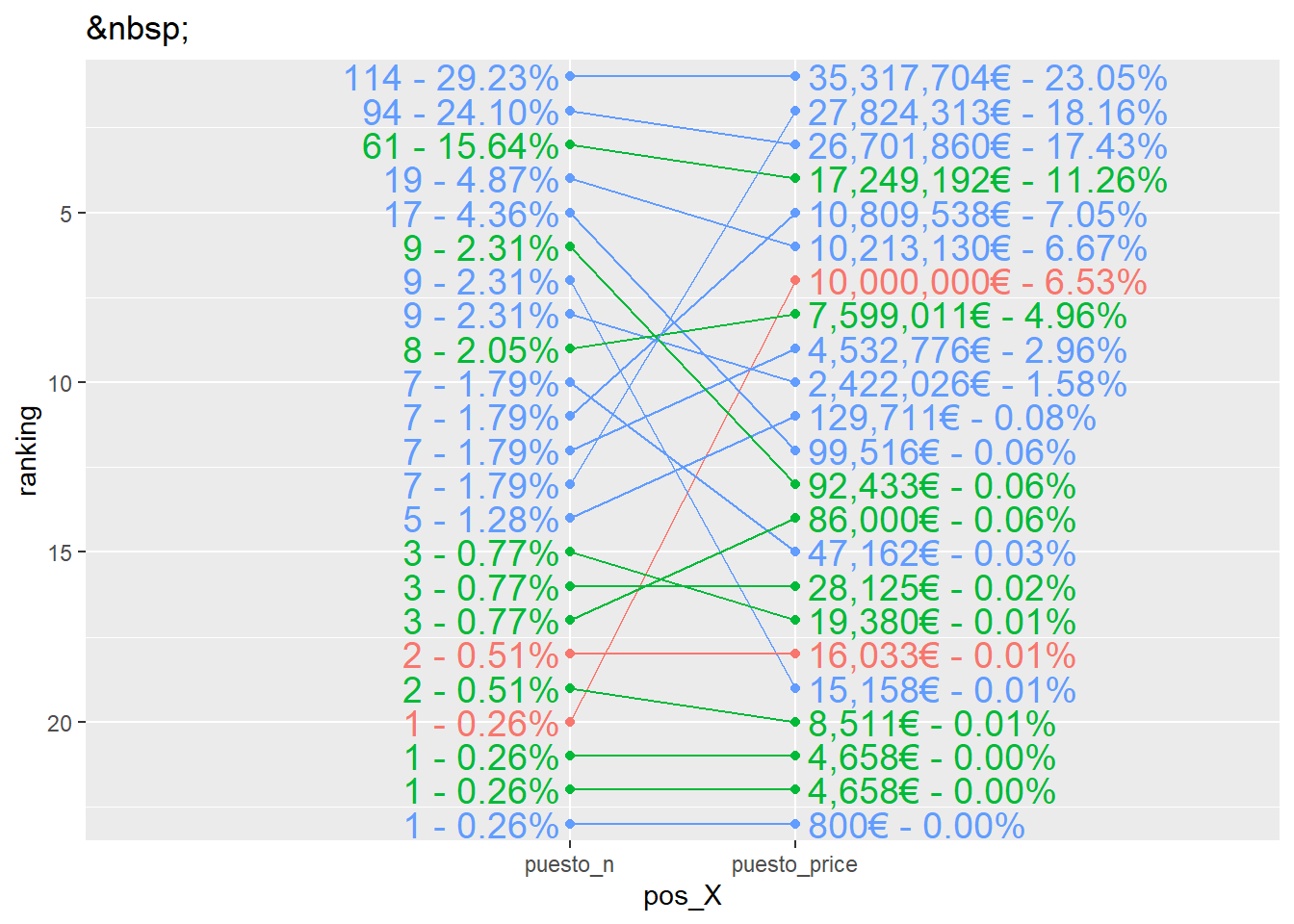
Gráfico de líneas
En este caso usamos el conjunto de datos pivotado para poder dibujar las líneas correctamente. Añadimos las etiquetas correspondientes a cada una de las columnas que se generan concatenando varios datos.
Además, invertimos el eje Y para que los elementos se posicionen correctamente. También añadimos algo de espacio para que se lean todos los textos jugando con los argumentos limits = y expand = de las escalas correspondientes.
Finalmente, el título es   (espacio en blanco en HTML) para que la barra del título tenga las dimensiones correctas pero no muestre ningún texto, una vez que apliquemos las modificaciones a la apariencia de los gráficos.
IMPORTANTE: para que la función dollar_format() del paquete scales funcione correctamente, la variable a la que se le pasará la función se da fuera de la función propiamente dicha.
scales::dollar_format(prefix = "", suffix = "€")(price_art_sum)
(
slope <- ggplot(datos_pivot,
aes(pos_X, ranking, group = articles, color = as.factor(level))) +
geom_line() +
geom_point(size = 1.5) +
geom_text(
data = datos_pivot %>% filter(pos_X == "puesto_n"),
aes(
x = pos_X,
y = ranking,
label = paste0(art_n, " - ", scales::percent(tot_n_prop, accuracy = 0.01))
),
hjust = 1,
nudge_x = -0.04,
size = 5
) +
geom_text(
data = datos_pivot %>% filter(pos_X == "puesto_price"),
aes(
x = pos_X,
y = ranking,
label = paste0(
scales::dollar_format(prefix = "", suffix = "€")(price_art_sum),
" - ",
scales::percent(price_tot_prop, accuracy = 0.01)
)
),
hjust = 0,
nudge_x = 0.055,
size = 5
) +
scale_y_continuous(trans = "reverse", expand = c(0, 0.5)) +
scale_x_discrete(expand = c(0.15, 2)) +
guides(color = FALSE) +
labs(title = " ")
)
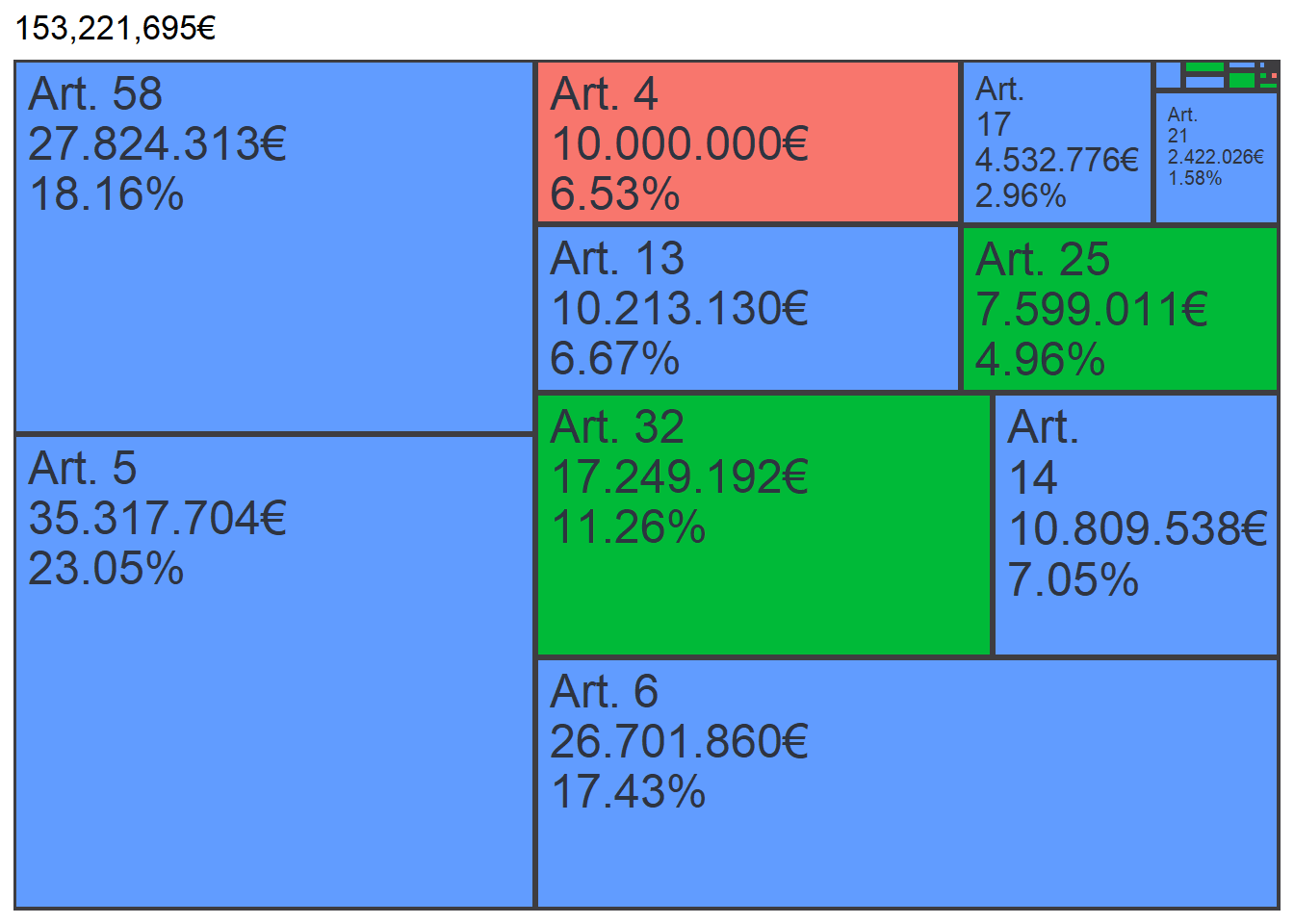
Treemap
Para crear el gráfico de tipo treemap usamos el paquete treemapify.
(treemap <- ggplot(datos, aes(
area = price_art_sum,
subgroup = price_art_sum,
label = paste0("Art. ", articles, "\n", scales::dollar_format(prefix ="", suffix ="€", big.mark =".", decimal.mark = ",")(price_art_sum), "\n", scales::percent(price_tot_prop, accuracy = 0.01)),
fill = as.factor(level)
)) +
geom_treemap() +
geom_treemap_text(
grow = FALSE,
reflow = TRUE,
color = "#2e3440",
padding.x = grid::unit(2, "mm"),
padding.y = grid::unit(2, "mm")
) +
geom_treemap_subgroup_border(colour = "#3e3d40", size = 3) +
guides(fill = FALSE) +
labs(title = scales::dollar_format(prefix="",suffix = "€")(sum(datos_pivot$price_art_sum) / 2))
)
Listas de artículos
Vamos a generar dos listas de artículos:
- Artículos sancionados, que tienen que alinearse correctamente con el gráfico de barras por número de infracciones.
- A modo de información contextual, también mostraremos una lista con los artículos sancionables que NO aparecen en los datos. Para este gráfico usaremos el conjunto de datos
nulosque hemos creado anteriormente. Facetaremos esta lista por tipo de multa. Este gráfico no forma parte del bloque principal, por lo que el título está estilizado de una forma distinta al resto de los gráficos.
En ambas listas mostraremos el título del artículo.
(
lista_articulos_si <-
ggplot(
data = datos_pivot %>% filter(pos_X == "puesto_n"),
aes(1, ranking, color = as.factor(level))
) +
geom_text(aes(label = paste0(
"Art. ", articles, " - ", title
)), hjust = 0, size = 5) +
scale_y_continuous(trans = "reverse", expand = c(0, 0.5)) +
scale_x_continuous(limits = c(0.99, 12)) +
guides(color = FALSE) +
labs(title = "Artículo infringido")
)
(
lista_articulos_no <-
ggplot(nulos, aes(1, ranking, color = as.factor(level))) +
geom_text(aes(label = paste0(
"Art. ", articles, " - ", title
)), hjust = 0, size = 4) +
facet_wrap( ~ level, nrow = 1) +
scale_y_continuous(trans = "reverse", expand = c(0, 0.5)) +
scale_x_continuous(limits = c(0.99, 12)) +
guides(color = FALSE) +
labs(title = "Artículos no sancionados") +
theme(
plot.title = element_textbox_simple(
color = "#d8dee9",
size = 16,
padding = margin(5.5, 5.5, 5.5, 5.5),
width = unit(0.99, "npc"),
halign = 0
),
plot.margin = unit(c(1, 1, 2, 1), "cm"),
strip.text = element_blank()
)
)
Apariencia y composición
Una vez que hemos creado los gráficos que usaremos como base, podemos pasar a modificar su apariencia y a generar la composición final.
Tema
Creamos una paleta de colores y modificamos el título del tema theme_void() que aplicaremos a todos los gráficos (esta modificación sólo afectará a los gráficos que no tengan ya el título modificado).
colores <- c("#d08770", "#8fbcbb", "#81a1c1")
theme_set(theme_void(base_size = 11, base_family = "Bahnschrift"))
theme_update(plot.title = element_textbox_simple(color = "#2e3440", fill = "#d8dee9", size = 16, padding = margin(5.5, 5.5, 5.5, 5.5), width = unit(0.99, "npc")))Composición
Para la composición final usaremos patchwork
- Igualamos las dimensiones de los gráficos para que se alineen correctamente
- Creamos el sistema de retícula: patchwork permite indicar las retículas de varias formas: operadores (
+,-,|,/), mediante letras o números, o indicando expresamente las áreas que ocuparán cada uno de los gráficos. Esta última opción es probablemente la más compleja, pero también la más versátil. En cualquier caso, si indicamos el sistema de esta forma, no debemos combinarlo con el de operadores (más allá del operador+, ya que es posible generar un error de interpretación).
max_dims <- get_max_dim(lista_articulos_si, items, slope, cuantia, treemap)
set_dim(lista_articulos_si, max_dims)
set_dim(items, max_dims)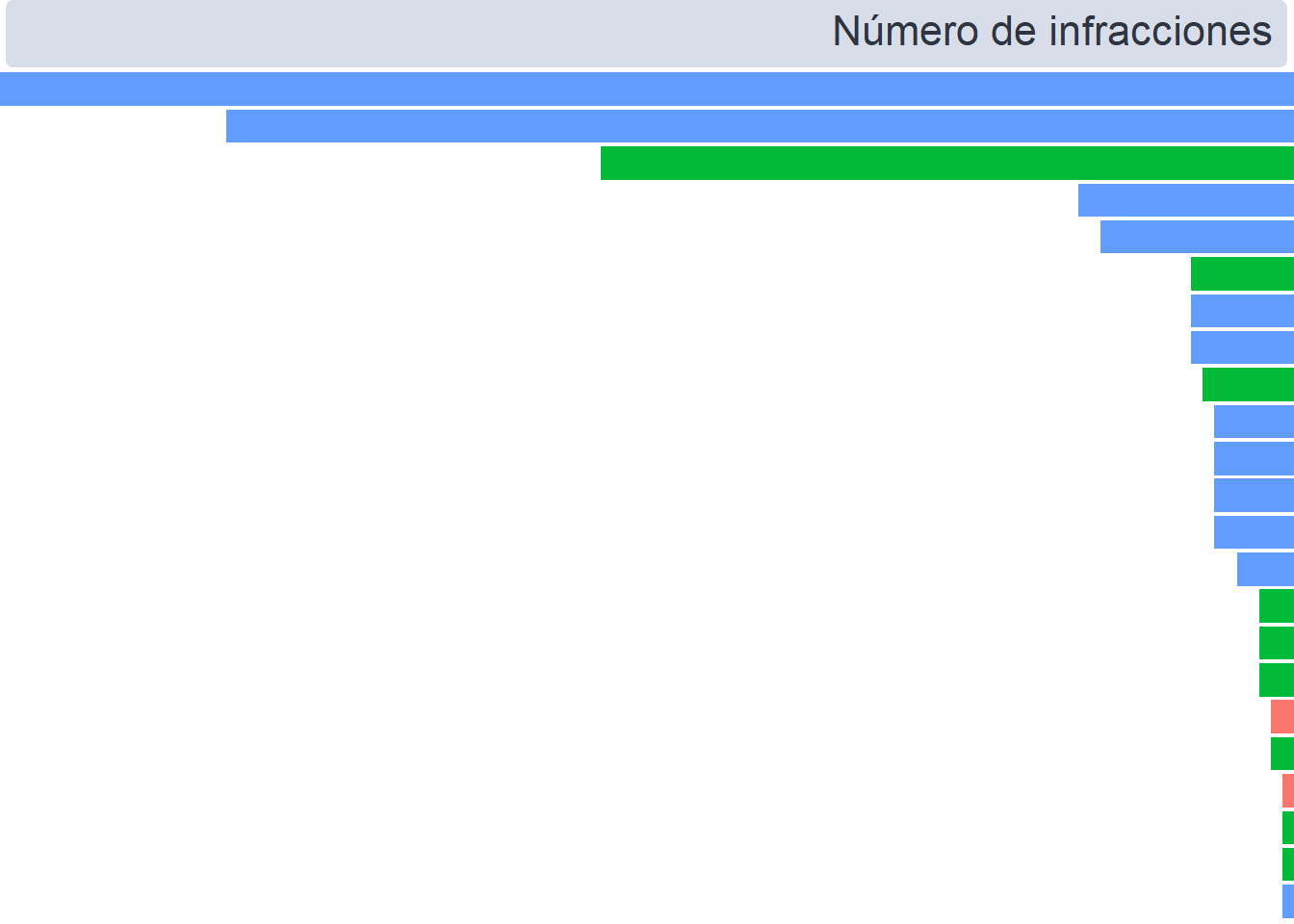
set_dim(slope, max_dims)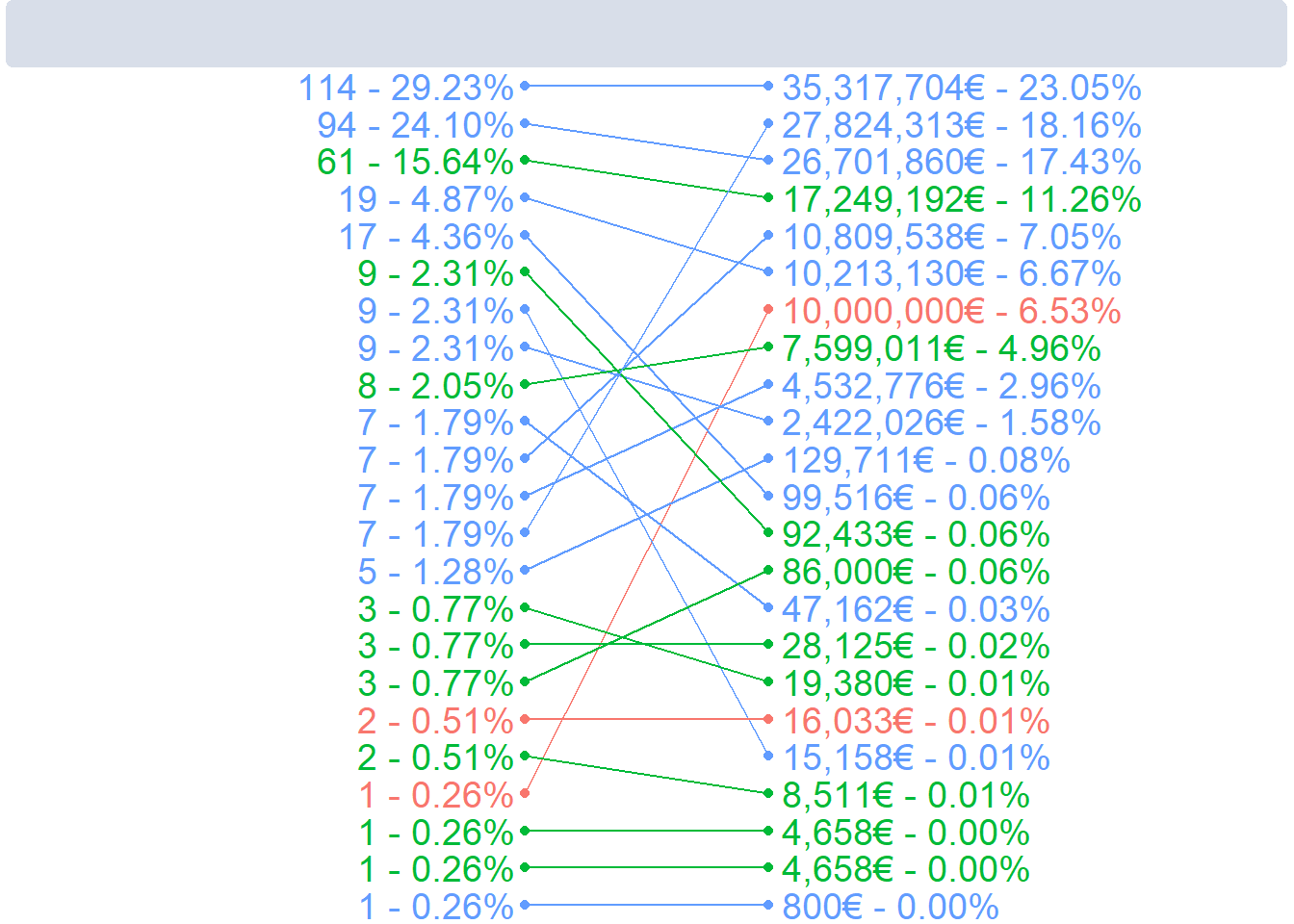
set_dim(cuantia, max_dims)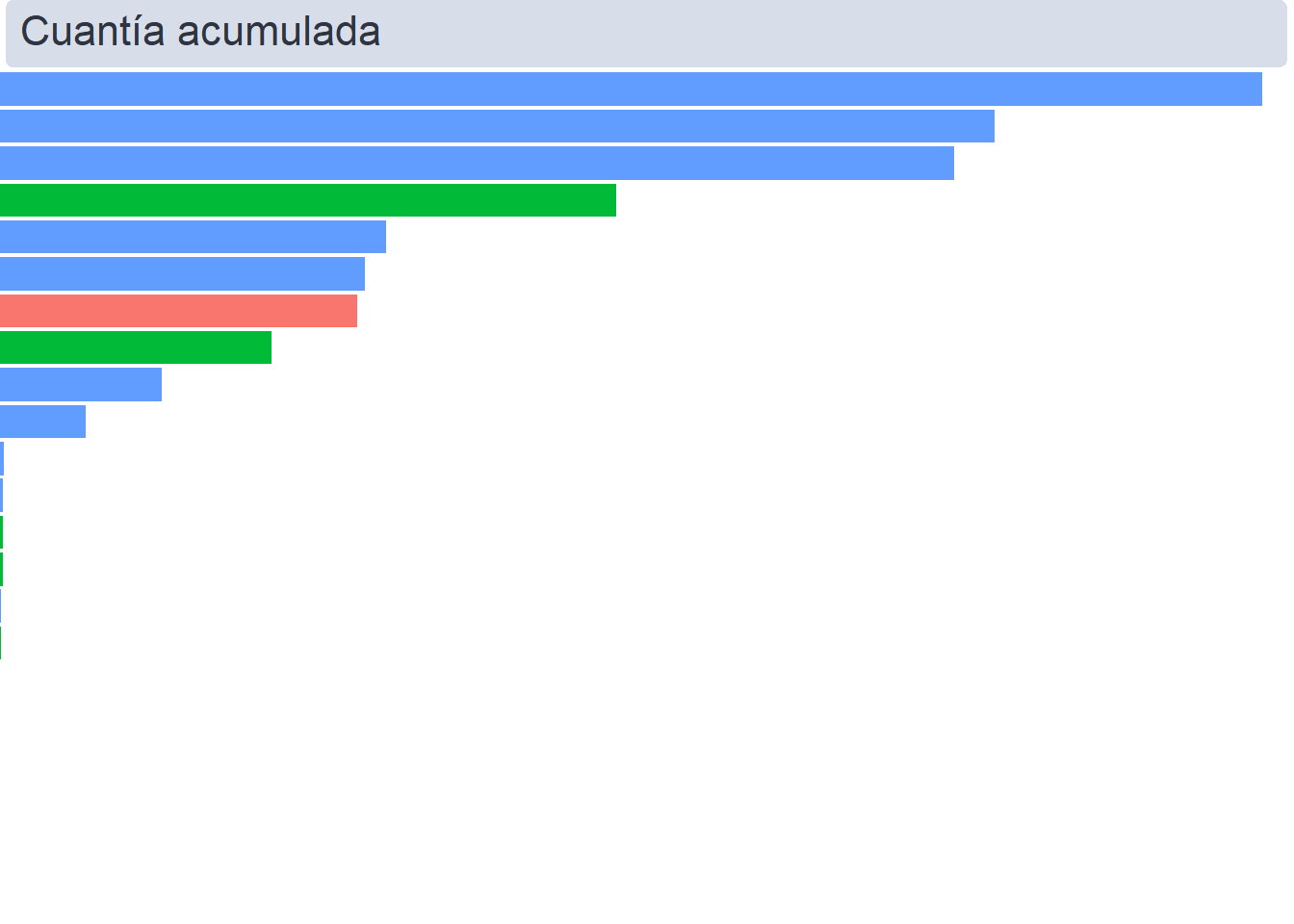
set_dim(treemap, max_dims)
layout <- c(
area(1,5,1,7),
area(2,1,3,2),
area(2,3,3,3),
area(2,4,3,5),
area(2,6,3,6),
area(2,7,3,7)
)
plot(layout)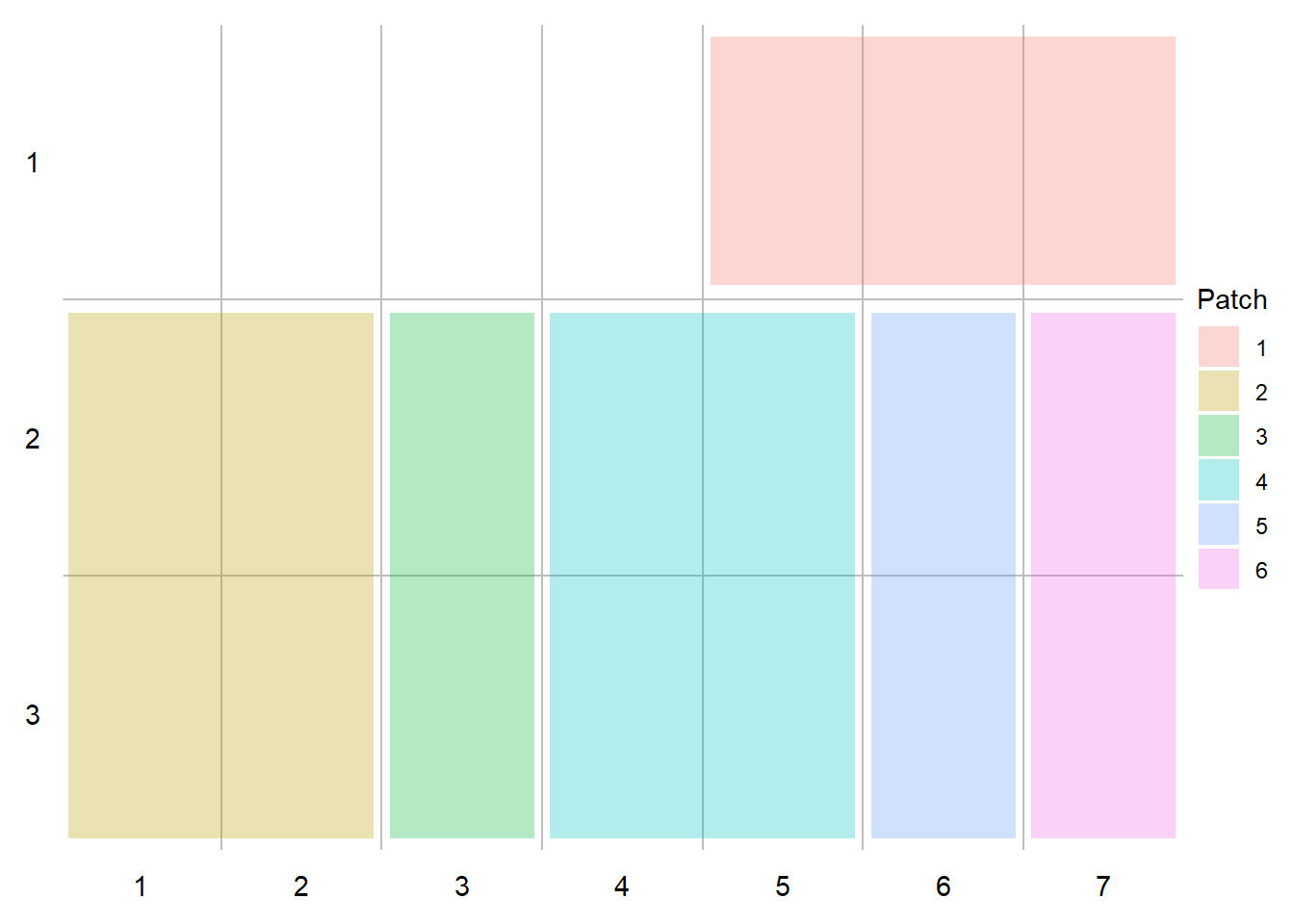
infografia <- lista_articulos_no +
lista_articulos_si + items + slope + cuantia + treemap +
plot_layout(design = layout) &
plot_annotation(subtitle = "<span style='font-size:20pt;font-weight:bold;'>**Multas por la GDPR desglosadas por artículos**</span><br><br>El artículo 83 de la GDPR recoge <span style='color:#8fbcbb'>multas de hasta **10.000.000 €**</span> y <span style='color:#81a1c1'>multas de hasta **20.000.000 €**</span> (los artículos <span style='color:#d08770'>83 y 4</span> parecen estar<br>mal codificados, ya que no comportan cuantías económicas).<br><br>Las multas analizadas pueden recoger más de una infracción de distintos artículos de la ley; los datos de las multas se han desglosado<br>por artículo, a fin de poder análizar cuáles son los artículos más infringidos, <br>así como la cuantía acumulada por cada artículo.<br><br>**NOTA**: no hay datos desagregadosen para aquellos casos en los que se ha multado más de una infracción, por lo que se ha procedido<br>a dividir el monto total entre el número de artículos infringidos.",
caption ="@neregauzak | #tidytuesday 2020-04-21 | data: privacyaffairs.com") &
scale_color_manual(values = colores) &
scale_fill_manual(values = colores) &
theme(plot.background = element_rect(fill = "#2e3440", color = "#2e3440"),
plot.subtitle = element_markdown(color = "#d8dee9", size = 16, margin = unit(c(5, 5, 10, 5), "mm")),
plot.caption = element_markdown(color = "#d8dee9", size = 16, margin = unit(c(5,5,5,5),"mm"))
)
Lamentablemente, no he dado con la forma de hacer “flotar” (a la CSS) el bloque con el título y el subtítulo, por lo que el montaje final lo he terminado con Gimp (simplemente consiste en bajar es bloque y recortar la imagen).
ggsave("infografia.png", infografia, dpi = 96, width = 25, height = 15)Resultado final (con mínima edición en gimp)